Gen
Gen là một đoạn xác định của phân tử acid nucleic có chức năng di truyền nhất định.[1][2][3][4] Trong hầu hết các trường hợp, phân tử acid nucleic này là DNA, rất ít khi là RNA (trường hợp gen là RNA hiện mới chỉ phát hiện ở một số virut).

Thuật ngữ này dịch theo phiên âm kết hợp Việt hoá từ tiếng Anh gene, cũng như từ tiếng Pháp gène (phát âm Quốc tế đều là /jēn/). Trong sinh học phổ thông cũng viết là gen (đọc là gien hoặc zen).[4][5] Gen có thể tạo ra sản phẩm của nó, gọi là sản phẩm của gen.
Thuật ngữ "gen" đóng vai trò cơ bản thiết yếu và quan trọng hàng đầu trong di truyền học. Nội hàm của thuật ngữ "gen" đã thay đổi nhiều kể từ khi di truyền học (genetics - tức khoa học về gen) ra đời (từ năm 1900) cho đến thế kỷ XIX hiện nay. Trong sinh học phân tử hiện đại cũng như di truyền học phân tử hiện đại, tính từ đầu năm 2000 đến nay, đã có ít nhất 6 định nghĩa mới về gen.[6] Bài viết này mới chỉ đề cập đến nội hàm của thuật ngữ gen ở thời kỳ mà nhiều nhà nghiên cứu lịch sử di truyền học gọi là "thời kỳ tân cổ điển" của di truyền học (khoảng từ những năm 1940 đến những năm 1970) và ít nhiều đề cập tới nội hàm tương đối mới đến những năm 1980.
Trong quá trình biểu hiện gen, trước tiên DNA được sao chép sang RNA. Phân tử RNA hoặc là có chức năng biệt hóa trực tiếp hoặc làm khuôn mẫu trung gian để tổng hợp lên protein thực hiện một chức năng nào đó. Sự chuyển giao gen đến các sinh vật thế hệ con cháu là cơ sở của tính thừa kế các tính trạng kiểu hình. Các gen tạo thành từ các trình tự DNA khác nhau gọi là kiểu gen. Kiểu gen cùng với các yếu tố môi trường và phát triển xác định lên tính trạng kiểu hình. Đa số các tính trạng sinh học chịu ảnh hưởng bởi nhiều gen (polygene, tức một tính trạng do nhiều gen khác nhau quyết định gọi là tương tác gen) cũng như tương tác giữa gen với môi trường. Một số tính trạng di truyền có thể trông thấy ngay lập tức, ví như màu mắt hoặc số chi, và một số khác thì không, như nhóm máu, nguy cơ mắc các bệnh, hoặc hàng nghìn quá trình sinh hóa cơ bản cấu thành sự sống.
Gene có thể thu nạp các đột biến sinh học nằm trong trình tự của chúng, dẫn đến những biến thể, gọi là các allele, trong quần thể. Các allele này mã hóa một số phiên bản hơi khác nhau của cùng một protein, làm biểu hiện tính trạng kiểu hình khác nhau. Việc sử dụng thuật ngữ "có một gen" (v.d., "các gen tốt," "gen màu tóc") thông thường nhắc tới việc bao gồm một allele khác nữa của cùng chung một gen.
Khái niệm gen liên tục được tinh chỉnh để cho phù hợp với những hiện tượng mới khám phá gần đây.[7] Ví dụ, các vùng điều hòa của một gen có thể nằm rất xa các vùng mã hóa của nó, và các vùng mã hóa này có thể xen kẽ bởi các đoạn exon. Một số virus lưu trữ bộ gen của chúng trong RNA thay vì ở DNA và một số sản phẩm gen là những RNA không mã hóa có chức năng chuyên biệt. Do đó, theo nghĩa rộng, định nghĩa khoa học hiện đại về gen là bất cứ đoạn locus di truyền được, đoạn trình tự trong bộ gen ảnh hưởng tới các tính trạng của sinh vật được biểu hiện thành sản phẩm chức năng hoặc tham gia điều hòa biểu hiện gen.[8][9]
Thuật ngữ gen do nhà thực vật học, sinh lý học thực vật và di truyền học người Đan Mạch Wilhelm Johannsen giới thiệu năm 1905.[10] Ông lấy gốc từ tiếng Hy Lạp cổ đại: γόνος, gonos, có nghĩa là thế hệ con cháu và sinh sản.
Lịch sử
sửa
Khám phá các đơn vị di truyền độc lập
sửaSự tồn tại của các đơn vị độc lập có khả năng di truyền được đề xuất lần đầu tiên bởi nhà thực vật học Gregor Mendel (1822–1884).[11] Từ năm 1854 đến 1863, trong một tu viện ở Brno, ông đã tiến hành trồng (gần 28.000 cây) và nghiên cứu các mẫu thế hệ con cháu của 12.835 cây thực vật đậu Hà Lan, theo dõi các đặc điểm khác biệt truyền từ thế hệ này sang thế hệ khác.[12][13][14] Ông miêu tả các đặc điểm này như là tổ hợp toán học 2n với n là số các đặc điểm khác nhau trong các cây đậu gốc. Mặc dù ông không sử dụng thuật ngữ gen, ông đã giải thích các kết quả theo thuật ngữ các đơn vị rời rạc có khả năng di truyền làm xuất hiện các đặc điểm thực tế quan sát được. Nội dung miêu tả này đã có trước phát hiện phân biệt của Wilhelm Johannsen về giữa kiểu gen (vật liệu di truyền của một sinh vật) và kiểu hình (các đặc điểm trông thấy của sinh vật đó). Mendel cũng lần đầu tiên chứng tỏ quy luật phân ly độc lập, sự khác biệt giữa các tính trạng trội và tính trạng lặn, sự khác biệt giữa dị hợp tử (heterozygote) và đồng hợp tử (homozygote), và hiện tượng di truyền không liên tục.
Trước khi có nghiên cứu của Mendel, ngành sinh học đã có một số tiến bộ như: nhờ phát minh kính hiển vi sơ khai của Antonie van Leeuwenhoek (thế kỷ XVII) đã mở đường cho việc quan sát thế giới vi sinh vật, sự ra đời thuyết tế bào của Matthias Schleiden và Theodor Schwann (1838, 1839). Nhìn chung quan niệm phổ biến về di truyền thời đó vẫn là di truyền các tính trạng tập nhiễm và di truyền hòa hợp (blending inheritance), cho rằng các cá thể thừa kế từ bố mẹ một hỗn hợp pha trộn các tính trạng, ví dụ như lai cây hoa đỏ với hoa trắng sẽ cho ra hoa hồng. Charles Darwin đã phát triển một lý thuyết về di truyền mà ông gọi là pangenesis (thuyết mầm, thuyết pangen), từ tiếng Hy Lạp cổ pan ("mọi, toàn thể") và genesis ("sự sinh") / genos ("nguồn gốc").[15][16] Darwin sử dụng thuật ngữ gemmule (mầm sinh) để miêu tả các hạt giả thuyết mà chúng được trộn với nhau trong quá trình sinh sản.
Tuy nhiên giới khoa học đương thời đã không hiểu và đánh giá được tầm vóc của khám phá Mendel sau khi ông công bố nghiên cứu vào năm 1866. Mãi đến năm 1900 ba nhà sinh học Hugo de Vries, Carl Correns, và Erich von Tschermak độc lập nhau đã thực hiện các thí nghiệm và đi đến các kết luận tương tự trước khi họ biết tới các nghiên cứu của Mendel.[17] Đặc biệt, năm 1889, Hugo de Vries xuất bản cuốn sách của ông Intracellular Pangenesis,[18] trong đó ông dự đoán rằng các tính trạng riêng biệt có từng đơn vị di truyền độc lập và sự kế thừa các tính trạng này trong sinh vật đến từ các hạt mầm. De Vries gọi những đơn vị này là "pangenes" (Pangens trong tiếng Đức), dựa theo lý thuyết pangenesis năm 1868 của Darwin.
Trong các năm 1902-1903, dựa trên các quan sát của nhiều nhà khoa học, trong đó có Walther Flemming về nhiễm sắc thể trong quá trình phân bào, hai nhà khoa học Walter Sutton và Theodor Boveri đã độc lập với nhau cùng khởi xướng Học thuyết di truyền nhiễm sắc thể. Trong bài báo của ông, Sutton nhấn mạnh vào sự quan trọng khi ông quan sát thấy nhóm NST lưỡng bội chứa hai tập hợp có hình thái (morphology) giống nhau, và trong giảm phân, mỗi giao tử chỉ nhận được một NST từ mỗi cặp NST tương đồng. Sau đó ông sử dụng quan sát này để giải thích các kết quả của Mendel bằng cách giả thiết rằng các gen nằm trên nhiễm sắc thể.[19]
Năm 1905, Wilhelm Johannsen đã giới thiệu các thuật ngữ 'gene', 'genotype' và 'phenotype'[10] và William Bateson đưa ra thuật ngữ 'di truyền học' ('genetic')[20].
Trong thập niên 1910, Thomas Hunt Morgan cùng với cộng sự đã xây dựng thành công thuyết di truyền nhiễm sắc thể (chromosome theory of inheritance) dựa trên đối tượng nghiên cứu là ruồi giấm Drosophila melanogaster. Học thuyết này xác nhận rằng gen là đơn vị cơ sở của tính di truyền nằm trên nhiễm sắc thể (ở trong nhân); trên đó các gen sắp xếp theo đường thẳng tạo thành nhóm liên kết.[21]
Sự khám phá DNA
sửaQuá trình nghiên cứu gen và di truyền tiếp tục đạt được những tiến bộ trong thế kỷ XX. Trước đó Friedrich Miescher (1869) đã khám phá ra một hỗn hợp trong nhân tế bào gọi là 'nuclein' mà sau đó Albrecht Kossel (1878) đã cô lập được thành phần không phải protein trong nuclein gọi là axit deoxyribonucleic. DNA được chứng tỏ là những phân tử chứa thông tin di truyền qua các thí nghiệm thực hiện trong thập niên 1940 đến thập niên 1950[22][23] (xem thí nghiệm Avery–MacLeod–McCarty, thí nghiệm Hershey–Chase). Nhờ kết quả nghiên cứu cấu trúc DNA bởi Rosalind Franklin và Maurice Wilkins bằng phương pháp tinh thể học tia X, đã giúp James D. Watson và Francis Crick đề xuất ra mô hình đúng về phân tử sợi xoắn kép DNA mà nguyên tắc ghép cặp nucleobase hàm ý giả thiết cho cơ chế sao chép vật liệu di truyền.[24][25]
Những năm đầu thập niên 1950, đa số các nhà sinh học có quan điểm cho rằng các gen trong một nhiễm sắc thể hoạt động giống như những đoạn rời rạc, không thể phân chia được bằng cách tái tổ hợp và sắp xếp như những hạt trên một chuỗi. Thí nghiệm của Seymour Benzer sử dụng các khuyết tật đột biến ở vùng rII của thể thực khuẩn T4 (1955-1959) đã chứng tỏ từng gen có một cấu trúc thẳng đơn giản và dường như là tương đương với một đoạn của sợi DNA.[26][27]
Bằng các thí nghiệm gây đột biến các gen liên quan đến các con đường sinh hóa trên nấm mốc bánh mỳ Neurospora crassa, năm 1941 George Beadle và Edward Tatum xác nhận mỗi gen kiểm soát phản ứng sinh hóa tổng hợp một enzyme đặc thù.[28] Kết quả này đưa hai ông đến giả thuyết một gen - một enzym về sau được chính xác hóa là một gen xác định chỉ một chuỗi polypeptide, cấu trúc bậc 1 của protein, trong đó có các enzyme.[29]
Từ những kết quả nghiên cứu thu nạp dần đã hình thành lên luận thuyết trung tâm của sinh học phân tử, phát biểu rằng các protein được dịch mã từ RNA, mà đến lượt RNA được phiên mã từ DNA. Tuy vậy, sau này luận thuyết được chỉ ra có những ngoại lệ, ví dụ như phiên mã ngược ở retrovirus. Ngành di truyền hiện đại nghiên cứu ở cấp độ DNA được biết đến là di truyền phân tử.
Năm 1972, Walter Fiers và cộng sự ở Đại học Ghent đã lần đầu tiên xác định được trình tự của một gen: đó là gen mã hóa cho protein vỏ bọc của thể thực khuẩn MS2.[30] Những phát triển sau đó của xác định trình tự DNA bằng kỹ thuật gián đoạn chuỗi bởi Frederick Sanger năm 1977 đã nâng cao hiệu quả giải trình tự và giúp nó trở thành công cụ thường xuyên trong các phòng thí nghiệm.[31] Một kỹ thuật tự động của phương pháp Sanger đã được áp dụng ở giai đoạn đầu của dự án giải mã bộ gen ở người.[32]
Thuyết tổng hợp hiện đại
sửaMột số lý thuyết đã được phát triển đầu thế kỷ XX nhằm kết hợp giữa di truyền Mendel với thuyết tiến hóa Darwin được gọi là thuyết tổng hợp hiện đại, một thuật ngữ do Julian Huxley giới thiệu.[33]
Các nhà sinh tiến hóa sau đó đã chỉnh sửa bổ sung khái niệm này, như quan điểm gen là đối tượng trung tâm của tiến hóa nêu ra bởi George C. Williams. Ông đề xuất một khái niệm gen tiến hóa như là một đơn vị của chọn lọc tự nhiên với định nghĩa: "nó là cái tách biệt và tái kết hợp với tần số phù hợp."[34]:24 Theo quan điểm này, phân tử gen phiên mã như là một đơn vị, và gen tiến hóa kế thừa như là một đơn vị. Các ý tưởng liên quan nhấn mạnh vào vai trò trung tâm của gen trong tiến hóa được Richard Dawkins thảo luận trong các cuốn sách phổ biến khoa học.[35][36]
Cơ sở phân tử
sửa
DNA
sửaHầu hết các sinh vật sống mã hóa gen của chúng trong những chuỗi dài DNA (axit deoxyribonucleic). DNA bao gồm một chuỗi cấu thành từ bốn loại tiểu đơn vị nucleotide, mỗi tiểu đơn vị cấu tạo bởi: một đường năm cacbon (2'-deoxyribose), một nhóm phosphat, và một trong bốn base adenine, cytosine, guanine, và thymine.[37]:2.1
Hai sợi DNA xoắn quanh nhau tạo thành chuỗi xoắn kép DNA với bộ khung xoắn đường-phosphat bao ngoài, và các base hướng vào trong mà adenine bắt cặp với thymine và guanine bắt cặp với cytosine. Sự bắt cặp base đặc biệt này xảy ra bởi vì ở mỗi adenine và thymine hình thành 2 liên kết hiđrô với nhau, trong khi ở mỗi cytosine và guanine hình thành 3 liên kết hiđrô với nhau. Do vậy hai sợi trong chuỗi xoắn kép liên kết với nhau tuân theo nguyên tắc bổ sung, với trình tự của các base bắt cặp sao cho các adenine của một sợi được bắt cặp với các thymine sợi kia, và cứ tương tự như thế.[37]:4.1
Do tính chất hóa học của phần dư pentose của các base, các sợi DNA có tính xác định hướng. Một đầu cuối của polyme DNA chứa nhóm hydroxyl lộ ra khỏi deoxyribose; vị trí này được gọi là đầu 3' của phân tử. Đầu cuối còn lại chứa nhóm phosphat lộ ra; hay còn gọi là đầu 5'. Hai sợi của chuỗi xoắn kép chạy theo hướng ngược nhau. Các quá trình tổng hợp axit nucleic, bao gồm tái bản DNA và phiên mã diễn ra theo chiều đầu 5'→3', bởi vì các nucleotide mới được ghép vào thông qua phản ứng khử nước khi sử dụng đầu 3' hydroxyl như là chất phản ứng nucleophile (chất cho một cặp electron để tạo thành liên kết hóa học).[38]:27.2
Sự biểu hiện gen được mã hóa trong DNA bắt đầu bằng quá trình phiên mã gen thành RNA, một loại axit nucleic thứ hai rất giống với DNA, nhưng các monome chứa đường ribose thay cho đường deoxyribose. RNA cũng chứa base uracil thay cho thymine. Các phân tử RNA ít bền hơn DNA và thường là sợi đơn trong dạng điển hình. Các gen mã hóa cho các protein chứa một dãy các trình tự ba nucleotide được gọi là các codon, phục vụ như các "từ" trong "ngôn ngữ" di truyền. Mã di truyền xác định lên protein trong quá trình dịch mã giữa codon và amino acid. Mã di truyền gần như là như nhau ở mọi sinh vật sống đã biết.[37]:4.1
Nhiễm sắc thể
sửa
Toàn bộ các gen trong một sinh vật hoặc trong một tế bào được gọi là bộ gen (genome) của chúng, mà chúng lưu trữ trong nhiễm sắc thể. Một NST chứa một chuỗi xoắn kép DNA rất dài (cùng với các protein hỗ trợ khác) mà trên đó có hàng nghìn gen mã hóa.[37]:4.2 Vùng NST tại đó chứa một gen được gọi là lô-cut. Mỗi lô-cut chứa một alen của gen; tuy nhiên, các thành viên trong một quần thể có thể có các allele khác nhau tại lô-cut, mà mỗi alen có thể giống nhau hoặc khác nhau ít nhiều về trình tự nuclêôtit.
Phần lớn các gen của sinh vật nhân thực được lưu trong một tập lớn, các sợi NST. Các NST được vo lại trong nhân tế bào như búi với sự hỗ trợ của các protein histone để tạo thành một đơn vị gọi là nucleosome. DNA đóng gói và cô đặc theo cách này được gọi là chromatin (chất nhiễm sắc).[37]:4.2 Cách thức DNA quấn bao quanh các histone, cũng như các sửa đổi hóa học của chính histone, giúp điều hòa một vùng DNA cụ thể nơi quá trình biểu hiện gen có thể thực hiện được. Ngoài các đoạn gene, trong nhiễm sắc thể của sinh vật nhân thực còn chứa các trình tự giúp đảm bảo quá trình tái bản DNA diễn ra bình thường mà không làm suy giảm các vùng đầu cuối DNA và giúp sắp xếp chúng vào các tế bào con trong quá trình phân bào: vùng khởi điểm tái bản (replication origin), telomere và tâm động (centromere).[37]:4.2 Vùng khởi điểm tái bản là những vùng trình tự nơi quá trình tái bản DNA được bắt đầu diễn ra (có thể tại một hoặc nhiều vị trí trên NST). Telomere (đầu mút) là những đoạn trình tự dài và lặp lại nằm ở những đoạn đầu hoặc cuối cùng của NST có chức năng ngăn cản sự thoái hóa của các vùng trình tự điều hòa và mã hóa trong quá trình tái bản DNA. Độ dài của các telomere giảm đi mỗi lần bộ gen được sao chép và được phát hiện có liên quan đến quá trình lão hóa tế bào.[40] Vị trí tâm động là nơi các sợi thoi (spindle fibre, hoặc microtubule) bám vào để tách hai chromatid chị em dính nhau ở tâm động trong quá trình phân bào.[37]:18.2
Sinh vật nhân sơ (vi khuẩn và vi khuẩn cổ) thông thường lưu giữ bộ gen của chúng trên một sợi nhiễm sắc thể dạng vòng có kích thước lớn (circular chromosome, xem DNA siêu xoắn). Tương tự, ở một số bào quan ở sinh vật nhân thực có chứa một NST mạch vòng còn sót loại mà trên đó có một số ít các gen.[37]:14.4 Thỉnh thoảng sinh vật nhân sơ bổ sung vào NST của chúng thêm những vòng nhỏ DNA gọi là plasmid, mà thường chỉ mã hóa một số gen và có thể trao đổi được giữa các cá thể. Ví dụ, các gen có khả năng giúp vi sinh vật kháng kháng sinh và mang lại cho plasmid khả năng tự sao chép độc lập giữa các tế bào, thậm chí của các chủng loài khác nhau, thông qua cơ chế chuyển gen ngang (horizontal gene transfer).[41]
Trong khi ở nhiễm sắc thể của sinh vật nhân sơ có mật độ tập trung gen tương đối cao, thì ở sinh vật nhân thực thường chứa các vùng DNA mà chức năng của nó không rõ ràng. Sinh vật nhân thực đơn bào đơn giản có tương đối ít lượng DNA như thế, trong khi bộ gen phức tạp của những sinh vật đa bào, bao gồm con người, chứa rất nhiều đoạn DNA mã vẫn chưa giải mã được chức năng của chúng.[42] Các nhà sinh học phân tử thường coi những vùng này là những đoạn DNA rác ("junk DNA"). Tuy nhiên, những phân tích gần đây gợi ý rằng mặc dù các vùng DNA mã hóa protein chỉ chiếm 2% trong bộ gen người, khoảng 80% số lượng base trong bộ gen có thể được biểu hiện, do đó "đoạn rác DNA" có thể bị sử dụng nhầm tên gọi.[9]
Cấu trúc
sửa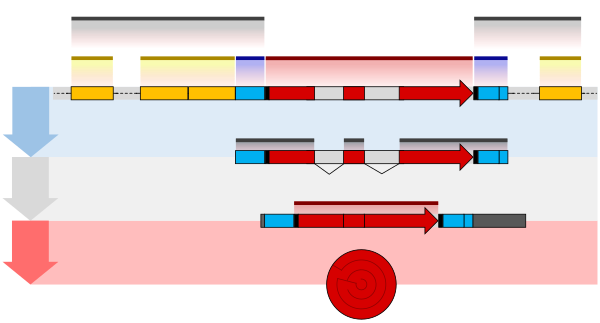

Cấu trúc của một gen chứa nhiều yếu tố mà những trình tự mã hóa protein thực sự chỉ là một phần nhỏ trong đó. Chúng bao gồm các vùng DNA không được phiên mã cũng như các vùng RNA không được dịch mã.
Tại hai bên khung đọc mở, mỗi gene chứa một trình tự điều hòa cần thiết cho sự biểu hiện của nó. Đầu tiên, gene cần một trình tự khởi động (promoter). Các yếu tố phiên mã (transcription factors) nhận ra và liên kết với vùng trình tự khởi động, sau đó RNA polymerase thực hiện khởi phát quá trình phiên mã.[37]:7.1 Việc nhận ra này thường nằm ở hộp TATA trong vùng khởi động. Một gene có thể có nhiều hơn một vùng khởi động, làm cho các RNA thông tin (mRNA) khác nhau ở độ dài của đầu 5'.[44] Những gene thường xuyên được phiên mã có những trình tự khởi động "mạnh" tức là tạo thành liên kết mạnh với các yếu tố phiên mã, do vậy khởi phát phiên mã ở tốc độ cao. Những gene khác có những vùng trình tự khởi động "yếu" mà liên kết yếu với các yếu tố phiên mã và do vậy sự phiên mã đối với các gen này xảy ra ít hơn.[37]:7.2 Các vùng trình tự khởi động ở sinh vật nhân thực có cấu trúc phức tạp hơn và khó nhận diện hơn so với ở sinh vật nhân sơ.[37]:7.3
Thêm vào đó, các gen có thể chứa những vùng điều hòa có độ dài hàng kilobase nằm ở bên trái hoặc bên phải khung đọc mở dẫn đến làm thay đổi mức độ biểu hiện. Những vùng này hoạt động bằng cách liên kết với các yếu tố phiên mã khiến cho DNA tạo thành mạch vòng do đó trình tự điều hòa (và yếu tố phiên mã bám vào) trở lên rất gần với RNA polymerase tại vị trí liên kết.[45] Ví dụ, các vùng tăng cường (enhancer) làm tăng tốc độ phiên mã bằng cách liên kết với một protein kích hoạt (activator protein) giúp kéo phân tử RNA polymerase đến vùng khởi động; ngược lại vùng bất hoạt (silencer) bám với protein ức chế (repressor protein) làm cho DNA trở lên ít hoạt động với RNA polymerase.[46]
Phân tử tiền mRNA (pre-mRNA) chứa những vùng không dịch mã ở cả hai đầu mà trong mỗi đầu chứa vị trí liên kết ribosome, vùng kết thúc (terminator) và các codon khởi đầu và codon kết thúc.[47] Thêm vào đó, ở hầu hết khung đọc mở của sinh vật nhân thực chứa các đoạn intron không dịch mã mà sẽ được loại bỏ trước khi các đoạn exon được dịch mã. Các trình tự ở cuối mỗi intron, quyết định các vị trí cắt (splice site, RNA splicing) để tạo ra mRNA thành thục cuối cùng, dùng để mã hóa cho protein hoặc sản phẩm RNA khác.[48]
Nhiều gene ở sinh vật nhân sơ được tổ chức thành các đơn vị operon, với nhiều trình tự mã hóa protein được phiên mã nằm trong nó.[49][50] Các gene trong một operon được phiên mã như là một mRNA liên tục, mà coi nó như là polycistronic mRNA. Thuật ngữ cistron trong bối cảnh này tương đương với khái niệm gen. Sự phiên mã của một operon của mRNA thường bị kiểm soát bởi phân tử ức chế (repressor), mà trạng thái hoạt động hay bị cấm của sự phiên mã phụ thuộc vào sự có mặt những chất chuyển hóa nhất định.[51] Khi phân tử ức chế hoạt động, nó bám vào một trình tự DNA nằm ở vị trí khởi đầu của operon, được gọi là vùng operator, làm cản trở sự phiên mã của operon; khi phân tử ức chế bất hoạt, sự phiên mã ở operon có thể xảy ra (xem ví dụ Lac operon). Các sản phẩm của gene operon thường có những chức năng liên quan và tham gia vào cùng mạng lưới điều hòa gene.[37]:7.3
Định nghĩa theo chức năng
sửaCác nhà sinh học phân tử gặp phải khó khăn khi muốn định nghĩa chính xác phần nào của một trình tự DNA chứa một gen.[7] Các vùng điều hòa của một gen như vùng tăng cường không cần thiết phải nằm gần với trình tự mã hóa trên mạch dài phân tử bởi vì các đoạn DNA trung gian có thể tạo vòng lồi ra (loop out) giúp mang gene và vùng trình tự điều hòa của nó đến gần nhau. Tương tự, các đoạn intron của một gen có thể dài hơn rất nhiều so với các đoạn exon của nó. Các vùng điều hòa thậm chí có thể nằm hoàn toàn trên nhiễm sắc thể khác và hoạt động từ xa (in trans) khi cho phép vùng điều hòa trên một nhiễm sắc thể đến gần với các gen đích nằm trên nhiễm sắc thể khác.[52][53]
Những nghiên cứu ban đầu trong di truyền phân tử gợi ra khả năng một gen tạo một protein. Khái niệm này (ban đầu gọi là giả thuyết một gen-một enzym) bắt nguồn từ bài báo có tầm ảnh hưởng năm 1941 bởi George Beadle và Edward Tatum công bố kết quả nghiên cứu các thí nghiệm gây đột biến trên nấm mốc bánh mỳ Neurospora crassa.[28] Norman Horowitz, một trong các cộng sự ban đầu tham gia vào nghiên cứu Neurospora, nhớ lại vào năm 2004 rằng "những thí nghiệm này là cơ sở của khoa học mà Beadle và Tatum từng gọi là di truyền sinh hóa. Thực sự các kết quả của họ đã khai sinh ra ngành di truyền phân tử và tất cả những phát triển sau đó."[54] Khái niệm một gen-một protein đã được tinh chỉnh dần từ lúc khám phá ra các gen có thể mã hóa nhiều protein bằng quá trình điều hòa cắt-nối có chọn lọc (alternative splicing) và các trình tự mã hóa tách thành những đoạn ngắn trên bộ gene mà các mRNA được ghép nối bằng quá trình xử lý cắt-nối chéo (trans-splicing).[9][55][56]
Một định nghĩa có tầm hoạt động rộng thỉnh thoảng được sử dụng để bao quát được tính phức tạp của nhiều hiện tượng phong phú, nơi một gen được định nghĩa như là hợp của các trình tự mã hóa cho một tập nhất quán các sản phẩm chuyên biệt có khả năng xen phủ lẫn nhau.[20] Định nghĩa này phân loại gene theo các sản phẩm có chức năng riêng (như protein hay RNA) hơn là theo những vị trí locus cụ thể trên đoạn DNA, với các yếu tố điều hòa được phân loại như là các vùng kết hợp với gene.[20]
Biểu hiện gene
sửaTrong mọi sinh vật, có hai bước cần thiết để đọc thông tin mã hóa trong DNA của gene và tổng hợp lên sản phẩm protein mà gene mã hóa cho. Đầu tiên, các đoạn DNA của gene được phiên mã thành RNA thông tin (mRNA).[37]:6.1 Thứ hai, mRNA được dịch mã thành protein.[37]:6.2 Các gene mã hóa trong RNA vẫn phải trải qua bước đầu tiên, nhưng không nhất thiết dịch mã thành protein.[57] Quá trình tổng hợp ra một phân tử chức năng sinh học hoặc là RNA hay protein được gọi là biểu hiện gen, và phân tử tạo thành được gọi là sản phẩm gene.
Mã di truyền
sửa
Trình tự nucleotide của DNA trong một gen xác định lên trình tự amino acid tương ứng của protein thông qua mã di truyền. Tập hợp các bộ ba nucleotide, gọi là bộ ba mã hóa hay codon, mà mỗi codon mã hóa cho một amino acid.[37]:6 Nguyên lý phát biểu rằng cứ ba base trong trình tự DNA mã hóa cho mỗi amino acid được minh chứng bằng thí nghiệm năm 1961 khi tạo đột biến dịch chuyển khung trong gene rIIB của thể thực khuẩn T4[58] (xem thí nghiệm Crick, Brenner và cộng sự).
Ngoài ra, một "codon khởi động", và ba "codon kết thúc" đánh dấu sự bắt đầu và kết thúc của vùng mã hóa protein. Có tất cả 64 codon khả dĩ (vì có bốn nucleotide ở mỗi một trong ba vị trí, do vậy tổ hợp có tất cả 43 codon) và trong tự nhiên chỉ có 20 amino acid cơ bản; do vậy số bộ ba là thừa và có nhiều codon cùng mã hóa cho một amino acid. Sự tương ứng giữa các codon và amino acido gần như là phổ biến rộng rãi ở mọi sinh vật sống đã biết trên Trái Đất.[59]
Phiên mã
sửaPhiên mã tạo ra phân tử RNA sợi đơn được biết đến là mRNA, mà các trình tự nucleotide trong nó tuân theo nguyên tắc bổ sung với của DNA làm gốc để phiên mã nó.[37]:6.1 mRNA có vai trò làm khuôn mẫu trung gian giữa DNA của gene và sản phẩm protein cuối cùng. DNA của gene được sử dụng làm khuôn để tổng hợp lên mRNA theo nguyên tắc ghép cặp bổ sung. mRNA khớp với trình tự của dải mã hóa (coding strand) trong DNA của gene bởi vì nó được tổng hợp như là sợi bổ sung của dải khuôn mẫu (template strand). Phiên mã được thực hiện bằng enzyme gọi là RNA polymerase, khi nó đọc và thực hiện trượt theo dải khuôn mẫu theo hướng đầu 3' đến đầu 5'; và tổng hợp lên RNA theo hướng ngược lại từ đầu 5' đến đầu 3'. Để khởi phát phiên mã, phân tử polymerase đầu tiên nhận ra và bám vào vùng khởi động của gen. Do vậy, cơ chế chính của điều hòa biểu hiện gen là ngăn chặn hoặc cô lập vùng khởi động, hoặc thông qua các phân tử ức chế (repressor) có chức năng ngăn chặn polymerase, hoặc bằng cách tổ chức DNA sao cho không thể tiếp cận được vùng khởi động.[37]:7
Ở sinh vật nhân sơ, quá trình phiên mã xảy ra trong tế bào chất; đối với phân tử phiên mã rất dài, sự dịch mã có thể bắt đầu tại đầu 5' của RNA trong khi ở đầu 3' của nó vẫn đang trong quá trình phiên mã. Ở sinh vật nhân thực, phiên mã xảy ra trong nhân tế bào, nơi lưu giữ DNA và nhiễm sắc thể. Phân tử RNA được tổng hợp bằng polymerase được gọi là bản sao sơ cấp (primary transcript) và trải qua một quá trình sửa đổi hậu phiên mã (post-transcriptional modification) trước khi trở thành mRNA thành thục và được chuyển ra khỏi nhân vào tế bào chất để chuẩn bị cho dịch mã. Một trong những sửa đổi được thực hiện đó là cắt-nối các đoạn intron là những trình tự trong vùng phiên mã nhưng không mã hóa cho protein. Cơ chế cắt-nối có chọn lọc (alternative splicing) có thể cho các bản sao thành thục từ cùng một gen nhưng mRNA có trình tự khác vào do vậy nó mã hóa cho những protein khác. Đây là cơ chế điều hòa chính ở tế bào nhân thực và cũng xuất hiện ở một vài tế bào nhân sơ.[37]:7.5[60]
Dịch mã
sửa
Dịch mã là quá trình trong đó một phân tử mRNA thành thục được sử dụng là khuôn mẫu để tổng hợp lên protein mới.[37]:6.2 Dịch mã được thực hện bằng các ribosome, những phức hợp lớn chứa RNA và protein chịu trách nhiệm thực hiện các phản ứng hóa sinh để ghép nối thêm những amino acid mới do tRNA mang đến tạo thành một chuỗi polypeptide đang dài dần ra dựa trên liên kết peptide. Mã di truyền được đọc ba nucleotide trong một lần, theo các đơn vị gọi là codon mã hóa, thông qua tương tác với các phân tử RNA biệt hóa gọi là RNA vận chuyển (tRNA). Mỗi tRNA có ba base không được ghép cặp gọi là các codon đối mã (anticodon) mà bắt cặp bổ sung với codon nó đọc được từ mRNA. tRNA thông qua liên kết cộng hóa trị gắn với amino acid mà chỉ khớp riêng với codon của tRNA đó. Khi tRNA bắt khớp với codon bổ sung trên dải mRNA, ribosome lập tức gắn amino acid nó mang tới vào chuỗi polypeptide đang được tổng hợp, mà có chiều từ đầu amin đến đầu carboxyl. Trong lúc và sau tổng hợp, hầu hết protein mới hình thành phải trải qua bước uốn gập về cấu trúc ba chiều hoạt động trước khi chúng thực hiện tham gia các chức năng trong tế bào hoặc được đẩy ra khỏi tế bào.[37]:3
Điều hòa
sửaCác gene được điều hòa sao cho chúng chỉ biểu hiện khi các sản phẩm gene ở mức cần thiết, vì quá trình biểu hiện tiêu tốn những nguồn dự trữ hạn chế.[37]:7 Một tế bào điều hòa biểu hiện các gen của nó phụ thuộc vào môi sinh (ví dụ chất dinh dưỡng nhiều hay ít, nhiệt độ và các sức ép-stress), môi trường bên trong tế bào (ví dụ chu kỳ phân bào, trao đổi chất, trạng thái lây nhiễm), và vai trò cụ thể của nó trong một sinh vật đa bào. Biểu hiện gene có thể được điều hòa ở bất kỳ một bước nào: từ lúc khởi phát phiên mã, đến xử lý RNA, đến sửa đổi sau dịch mã đối với protein. Sự điều hòa các gen kiểm soát trao đổi chất của đường lactose ở E. coli (lac operon) là một trong những cơ chế điều hòa đầu tiên được François Jacob và Jacques Monod miêu tả vào năm 1961.[51]
Các gene sinh RNA không mã hóa
sửaMột gene mã hóa protein điển hình thường đầu tiên sao chép sang RNA như là một phân tử trung gian trong quá trình tổng hợp ra protein cuối cùng.[37]:6.1 Trong trường hợp khác, các phân tử RNA là những sản phẩm có chức năng chuyên biệt, như vai trò trong tổng hợp RNA ribosome và RNA vận chuyển. Một số RNA được biết đến là các ribozyme có khả năng hoạt động như enzyme, và microRNA có vai trò điều hòa. Trình tự DNA từ đó mà RNA được phiên mã thành các RNA có chức năng chuyên biệt được gọi là các gene sinh RNA không mã hóa.[57]
Ở một số virus chúng lưu trữ toàn bộ bộ gene của chúng trong dạng của RNA, và không hề chứa một trình tự DNA nào.[61][62] Bởi vì chúng sử dụng RNA để lưu giữ các gene, các tế bào vật chủ có thể tổng hợp lên các protein cần thiết cho virus ngay khi chúng lây nhiễm vào vật chủ và không cần phải đợi xảy ra giai đoạn phiên mã.[63] Mặt khác, ở các RNA retrovirus, như HIV, chúng đòi hỏi phải có quá trình phiên mã ngược từ bộ gene của chúng là RNA sang DNA trước khi protein của virus được tổng hợp ra. Di truyền học ngoài gene (epigenetics) do RNA trung gian cũng đã được quan sát thấy ở một số thực vật nhưng rất hiếm có ở động vật.[64]
Di truyền
sửa
Bộ gene các sinh vật được kế thừa từ gene trong thế hệ bố mẹ của chúng. Các sinh vật sinh sản vô tính chỉ đơn giản là kế thừa bản sao đầy đủ của bộ gene bố mẹ chúng. Các sinh vật sinh sản hữu tính có hai bản sao ở mỗi nhiễm sắt thể bởi vì chúng thừa hưởng một bộ đầy đủ từ mỗi con cái và con đực.[37]:1
Di truyền Mendel
sửaTheo di truyền Mendel, các biến dị trong kiểu hình của một sinh vật (các đặc điểm vật lý và cư xử quan sát được) là một phần do những biến đổi trong kiểu gene (đặc biệt là các gen tương ứng). Mỗi gene xác định một tính trạng riêng với các trình tự khác nhau trên cùng một gen (các allele) làm xuất hiện nhiều kiểu hình khác nhau. Hầu hết các sinh vật nhân thực (như ở cây đậu Hà Lan mà Mendel dùng để nghiên cứu) có hai allele cho mỗi tính trạng, mỗi allele được kế thừa từ bố hoặc mẹ.[37]:20
Tại locus các allele có thể là trội hoặc lặn; các allele trội thể hiện những kiểu hình tương ứng khi nó ghép cặp với bất kỳ một allele khác của tính trạng, trong khi các allele lặn chỉ thể hiện kiểu hình tương ứng khi nó ghép cặp với cùng một bản sao allele khác. Nếu biết kiểu hình của sinh vật, có thể xác định được allele trội và allele lặn. Ví dụ, nếu allele xác định thân cây cao ở đậu Hà Lan là tính trạng trội so với allele xác định thân cây thấp, thì ở thực vật đậu thừa hưởng một allele allele cao từ bố mẹ và một allele thấp từ bố mẹ thì nó sẽ là thân cây cao. Nghiên cứu của Mendel chứng tỏ rằng các allele phân ly độc lập trong hình thành giao tử, hoặc các tế bào gốc, đảm bảo biến đổi ở thế hệ tiếp theo. Mặc dù di truyền Mendel vẫn là một mô hình tốt cho nhiều tính trạng xác định bởi các gen riêng rẽ (bao gồm một số bệnh di truyền hay gặp) nó không kể đến những quá trình sinh hóa trong tái bản DNA và phân bào.[65][66]
Tái bản DNA và phân bào
sửaCác sinh vật sinh trưởng, phát triển và sinh sản dựa vào sự phân bào; quá trình trong đó một tế bào phân chia thành hai tế bào con. Để thực hiện được như vậy đầu tiên trong nhân tế bào cần tiến hành sao chép từng gene trong bộ gene thông qua cơ chế tái bản DNA.[37]:5.2 Quá trình tái bản được thực hiện nhờ những enzyme chuyên biệt mà trong số đó là DNA polymerase, phân tử này thực hiện "đọc" một sợi trong hai sợi xoắn kép DNA đã được tháo xoắn, hay còn gọi sợi này là sợi khuôn, và tổng hợp lên một sợi bổ sung mới. Bởi vì chuỗi xoắn kép DNA được liên kết với nhau bởi các cặp base bổ sung, từ trình tự của một sợi có thể hoàn toàn xác định lên trình tự bổ sung; do vậy enzyme chỉ cần đọc một sợi là có thể tạo ra một bản sao đầy đủ. Quá trình tái bản DNA tuân theo nguyên tắc bán bảo toàn; tức là, bản sao của bộ gene thừa kế trong mỗi tế bào con chứa một sợi gốc từ bố mẹ và một sợi DNA mới tổng hợp.[37]:5.2
Tốc độ tái bản DNA trong tế bào sống lần đầu tiên được xác định là ở tốc độ kéo dài DNA của thể thực khuẩn T4 trong E. coli bị nhiễm phage và các nhà sinh học phát hiện thấy nó có một tốc độ nhanh đáng kinh ngạc.[67] Trong giai đoạn sao chép DNA ở nhiệt độ 37 °C, tốc độ kéo dài bằng 749 nucleotide trên một giây.
Sau khi quá trình tái bản DNA kết thúc, tế bào phải trải qua sự chia tách của hai bản sao bộ gene và phân chia thành hai tế bào có màng phân biệt.[37]:18.2 Ở sinh vật nhân sơ (vi khuẩn và vi khuẩn cổ) quá trình này tương đối đơn giản thể hiện qua sự phân chia đôi (binary fission), trong đó mỗi bộ gene trên mạch vòng gắn vào màng tế bào và được tách ra thành các tế bào khi màng tế bào lộn vào trong (invagination) và tách tế bào chất ra thành hai phần ngăn nhau bởi màng tế bào. Quá trình phân chia đổi xảy ra cực kỳ nhanh so với tốc độ phân bào ở sinh vật nhân thực. Tế bào của sinh vật nhân thực phân chia diễn ra phức tạp hơn như trong chu kỳ tế bào; sự tái bản DNA xảy ra trong pha S, trong khi quá trình tách nhiễm sắc thể và bào tương xảy ra trong pha M.[37]:18.1
Di truyền phân tử
sửa
Sự tái bản và truyền vật liệu di truyền từ một thế hệ tế bào sang thế hệ tiếp theo là cơ sở của di truyền phân tử, và là mối liên hệ giữa bức tranh phân tử với bức tranh cổ điển của gen. Sinh vật thừa hưởng những đặc tính từ bố mẹ bởi vì các tế bào con chứa các bản sao của gene từ trong tế bào của bố mẹ chúng. Ở các sinh vật sinh sản vô tính, ở thế hệ con sẽ chứa bản sao di truyền hay dòng hóa từ các sinh vật bố mẹ. Ở sinh vật sinh sản hữu tính, một giai đoạn đặc biệt của quá trình phân bào gọi là giảm phân tạo thành các tế bào giao tử hoặc tế bào mầm phôi đơn bội, và chỉ chứa gene trong nhiễm sắc thể đơn bội.[37]:20.2 Giao tử phát sinh từ con cái gọi là trứng hay ova, và giao tử phát sinh từ con đực gọi là tinh trùng. Hai giao tử kết hợp với nhau tạo thành hợp tử lưỡng bội trứng đã được thụ tinh, một tế bào trong nó chứa hai tập hợp gene, với một bản sao của mỗi gene đến từ con cái và một bản sao còn lại từ con đực.[37]:20
Trong quá trình phân bào giảm phân, thỉnh thoảng xuất hiện sự kiện tái tổ hợp di truyền hay trao đổi chéo ở một số đoạn giữa hai nhiễm sắc thể tương đồng, kéo theo sự trao đổi các gen giữa chúng. Ở sự kiện này, một đoạn DNA trên một chromatid được hoán vị bằng một đoạn DNA có độ dài bằng nhau nằm trên chromatid tương đồng khác chị em. Hiện tượng này có thể dẫn đến sự tổ chức lại các allele đã có liên kết với nhau.[37]:5.5 Quy luật phân ly độc lập của Mendel khẳng định mỗi gene từ bố hoặc mẹ cho mỗi tính trạng sẽ sắp xếp một cách độc lập trong giao tử; hay các allele của các gen khác nhau thì phân ly một cách độc lập với nhau trong quá trình hình thành giao tử. Điều này chỉ đúng cho những gene mà không nằm trên cùng một nhiễm sắc thể, hoặc nằm trên cùng một nhiễm sắc thể nhưng cách rất xa nhau. Hai gene nằm càng gần nhau trên cùng một nhiễm sắc thể, chúng sẽ càng có mặt cùng nhau trong giao tử và các tính trạng chúng biểu hiện sẽ xuất hiện cùng nhau thường xuyên; những gene nằm rất gần nhau hoặc cạnh nhau về cơ bản không bao giờ bị tách biệt bởi vì rất hiếm khi điểm trao đổi chéo sẽ xuất hiện giữa hai gene này. Đây là cơ sở của hiện tượng di truyền liên kết gene hoàn toàn (genetic linkage).[69]
Ruồi giấm Drosophila melanogaster đã được nhà di truyền học người Mỹ, Thomas Hunt Morgan (1866-1945), sử dụng trong nghiên cứu di truyền học từ những năm đầu của thế kỷ XX, trong khi đang làm việc tại Học viện Công nghệ California. Nhờ sử dụng ruồi giấm này, Morgan và các cộng sự của mình đã xây dựng thành công học thuyết di truyền nhiễm sắc thể. Lý thuyết này đã khẳng định gene - đơn vị di truyền then chốt đóng ba vai trò: (i) Gene là đơn vị chức năng, nghĩa là gene được xem như một thể thống nhất toàn vẹn kiểm soát một tính trạng cụ thể. (ii) Gene là đơn vị tái tổ hợp, nghĩa là gene không bị chia nhỏ bởi sự trao đổi chéo (vì theo quan điểm này, trao đổi chéo không xảy ra bên trong phạm vi một gen mà chỉ xảy ra giữa các gene); như thế gene được coi là đơn vị cấu trúc cơ sở của vật chất di truyền, nhiễm sắc thể. (iii) Gene là đơn vị đột biến, nghĩa là nếu đột biến xảy ra trong gene dù ở bất kỳ vị trí nào hoặc với phạm vi ra sao, chỉ gây ra một trạng thái cấu trúc mới tương ứng với một kiểu hình mới, kiểu hình đột biến, khác với kiểu hình bình thường. Tuy nhiên, quan niệm này vẫn còn chưa rõ ràng và không thực sự chính xác theo quan điểm của di truyền học hiện đại[68]
Các biến đổi ở mức phân tử
sửaĐột biến
sửaGiai đoạn tái bản DNA diễn ra phần lớn có độ chính xác cao, tuy vậy cũng có lỗi (đột biến) xảy ra.[37]:7.6 Tần suất lỗi ở tế bào sinh vật nhân thực có thể thấp ở mức 10−8 trên nucleotide trong mỗi lần tái bản,[70][71] trong khi ở một số virus RNA có thể cao tới mức 10−3.[72] Điều này có nghĩa là ở mỗi thế hệ, trong bộ gene ở người thu thêm 1–2 đột biến mới.[72] Những đột biến nhỏ xuất hiện từ quá trình tái bản DNA và hậu quả từ phá hủy DNA và bao gồm đột biến điểm trong đó một base bị thay đổi và đột biến dịch chuyển khung trong đó một base được thêm vào hay bị xóa. Hoặc là những đột biến này làm thay đổi gene theo cách làm sai nghĩa (missense mutation, thay đổi một codon làm nó mã hóa cho amino acid khác) hoặc làm cho gene trở nên vô nghĩa (nonsense mutation, làm quá trình tái bản DNA sớm kết thúc khi đọc đến codon kết thúc và sản phẩm gene là protein không hoạt động được).[73] Những đột biến lớn hơn có thể gây ra lỗi trong tái tổ hợp dẫn đến những bất thường ở nhiễm sắc thể (chromosomal abnormality) bao gồm nhân đôi một gen (gene duplication), xóa, sắp xếp lại hoặc đảo ngược những đoạn dài trong một NST. Thêm vào đó, cơ chế sửa chữa DNA có thể dẫn ra vài đột biến mới khi thực hiện sửa chữa những sai hỏng vật lý ở phân tử. Sự sửa chữa, ngay cả khi đi kèm với đột biến, là quan trọng hơn đối với sự tồn tại hơn là khôi phục lại bản sao chính xác, ví dụ khi thực hiện sửa chữa chuỗi xoắn kép bị gãy.[37]:5.4
Khi nhiều allele khác nhau của cùng một gen có mặt trong quần thể một loài thì hiện tượng này được gọi là đa hình (polymorphism). Phần lớn các allele khác nhau hoạt động tương tự nhau, tuy nhiên ở một số allele có thể làm xuất hiện các tính trạng kiểu hình khác nhau. Allele phổ biến nhất của một gen được gọi là kiểu dại (wild type), và những allele hiếm được gọi là allele đột biến. Biến dị di truyền trong tần số tương đối của các allele khác nhau trong một quần thể có nguyên nhân từ cả chọn lọc tự nhiên và biến động di truyền (genetic drift, những sự biến đổi ngẫu nhiên vô hướng về tần số allele trong tất cả các quần thể, nhưng đặc biệt là ở các quần thể nhỏ).[74]
Phần lớn các đột biến bên trong các gen là đột biến trung tính (neutral mutation), không có ảnh hưởng đến kiểu hình của sinh vật (đột biến lặng, silent mutation). Một số đột biến không làm thay đổi trình tự amino acid bởi vì một số codon mã hóa cho cùng một amino acid (đột biến đồng nghĩa, synonymous mutation). Các đột biến khác trở thành trung tính nếu tuy nó làm thay đổi trình tự amino acid, nhưng protein vẫn gập nếp và hoạt động bình thường với amino acid mới (đột biến bảo toàn, conservative mutation). Tuy nhiên, nhiều đột biến là có hại (deleterious mutation) hay thậm chí gây chết (lethal allele), và bị loại bỏ khỏi quần thể bằng quá trình chọn lọc. Rối loạn di truyền (genetic disorders) là kết quả của các đột biến có hại và có thể do đột biến tự phát trong cá thể bị ảnh hưởng, hoặc có thể di truyền sang thế hệ sau. Cuối cùng, có một tỷ lệ nhỏ các đột biến là có lợi (beneficial mutation), tăng cường độ phù hợp (fitness) ở sinh vật, và trở thành một trong những luận điểm quan trọng của thuyết tiến hóa tổng hợp hiện đại, vì trong chọn lọc có hướng dẫn đến tiến hóa thích nghi.[37]:7.6
Trình tự tương đồng
sửa
Gene có nguồn gốc tổ tiên chung gần nhất, và do vậy chia sẻ cùng một lịch sử khám phá, được biến đến có tính tương đồng.[75] Những gene này xuất hiện hoặc từ sự lặp đoạn gene bên trong bộ gene của sinh vật, nơi chúng được gọi là các gen môi sinh, hoặc là kết quả của sự phân tán gene sau một sự kiện hình thành loài,[37]:7.6 và thường thực hiện các chức năng giống nhau hoặc tương tự như ở sinh vật liên quan. Người ta thường giả sử rằng những gene này có sự giống nhau nhiều hơn so với gene môi sinh, mặc dù sự khác nhau là nhỏ.[76][77]
Mối liên hệ giữa các gen có thể đo được bằng cách so sánh sắp trình tự trong DNA của chúng.[37]:7.6 Độ giống nhau giữa các gen tương đồng được gọi là trình tự bảo toàn (conserved sequence). Theo thuyết tiến hóa phân tử trung tính, phần lớn những thay đổi trong trình tự của một gen không ảnh hưởng đến chức năng của nó và do vậy gene tích lũy các đột biến theo thời gian. Thêm vào đó, bất kỳ chọn lọc nào trên một gen sẽ làm cho trình tự của nó phân tán với tốc độ khác. Các gene chịu ảnh hưởng chọn lọc ổn định có tính ổn định cao và sự thay đổi đối với chúng diễn ra chậm trong khi các gen chịu ảnh hưởng chọn lọc định hướng thay đổi trình tự một cách nhanh chóng.[78] Sự khác nhau trong trình tự giữa các gen có thể được ứng dụng để phân tích phát sinh chủng loài để nghiên cứu các gen đã tiến hóa bằng cách nào và bằng cách nào mà các sinh vật trở lên có liên quan đến nhau.[79][80]
Nguồn gốc các gen mới
sửa
Nguồn gốc chung phổ biến ở các gen mới trong nòi giống sinh vật nhân thực là lặp đoạn gene, trong đó tạo ra một bản sao gene mới từ gene đã có trong bộ gene.[81][82] Những gene tạo ra này sau đó có thể phân tán trong trình tự và chức năng. Tập hợp các gen hình thành theo cách này tạo thành gia đình gene (gene family). Các nhà tiến hóa cho rằng lặp đoạn gene và mất gene trong một gia đình là phổ biến và là nguyên nhân chủ yếu dẫn đến sự đa dạng sinh học.[83] Thình thoảng, lặp đoạn gene có thể tạo ra một bản sao không hoạt động bình thường, hoặc bản sao chức năng chịu ảnh hưởng của đột biến làm mất chức năng; những gene không hoạt động này được gọi là gene giả (pseudogene).[37]:7.6
Các gene "mồ côi", mà trình tự không giống với một gen đã có nào, ít gặp hơn so với lặp đoạn gen. Ước tính số lượng gene mà không có trình tự tương đồng nằm bên ngoài con người từ 18[84] đến 60.[85] Hai nguồn chủ yếu của các gen mồ côi mã hóa protein đó là quá trình lặp đoạn gene theo sau bởi sự thay đổi trình tự cực lớn, như mối liên hệ gốc là không xác định được từ việc so sánh trình tự, và sự chuyển đổi mới từ một trình tự không mã hóa trước đó thành một gen mã hóa protein.[86] Các gene mới thường ngắn hơn và đơn giản hơn về cấu trúc so với các gen ở sinh vật nhân thực, mà chỉ có vài intron (nếu có).[81] Các nhà sinh tiến hóa cho rằng trong thời gian tiến hóa dài, gene mới sinh có thể chịu trách nhiệm cho một tỷ lệ đáng kể các gia đình gene bị giới hạn về mặt chủng loại.[87]
Quá trình chuyển gene ngang nhắc tới sự truyền vật liệu di truyền thông qua một cơ chế hơn là sự sinh sản. Cơ chế này là nguồn thường gặp tạo gene mới ở sinh vật nhân sơ, mà đôi lúc được cho là đóng góp nhiều hơn vào biến dị di truyền so với lặp đoạn gene.[88] Nó là một cách phổ biến để phát tán kháng thuốc kháng sinh, độc lực, và các chức năng trao đổi chất thích ứng.[41][89] Mặc dù chuyển gene ngang hiếm xảy ra ở sinh vật nhân thự, một số trường hợp tương tự đã được phát hiện ở bộ gene của sinh vật nguyên sinh và tảo chứa các gen có nguồn gốc từ vi khuẩn.[90][91]
Bộ gene
sửaBộ gene là tổng thể toàn bộ vật liệu di truyền của một sinh vật và bao gồm cả các gen và những trình tự không mã hóa.[92]
Số lượng gene
sửa
Kích thước bộ gene, và số lượng gene mã hóa ở mỗi loài sinh vật là khác nhau. Virus,[100] và viroid (mà hoạt động như là một gen RNA không mã hóa) có bộ gene nhỏ nhất.[101] Ngược lại, ở thực vật có những bộ gene cực kỳ lớn,[102] chẳng hạn ở cây lúa gạo chứa hơn 46.000 gene mã hóa protein.[103] Tổng số lượng gene mã hóa protein (bộ protein, proteome, trên Trái Đất) ước tính bằng 5 triệu trình tự.[104]
Mặc dù số lượng cặp base của DNA ở bộ gene người đã được biết đến từ thập niên 1960, ước tính số lượng gene có sự thay đổi theo thời gian khi định nghĩa về gene, và phương pháp xác định chúng liên tục được cập nhật và tinh chỉnh. Các dự đoán lý thuyết ban đầu về số lượng gene ở người cao tới mức 2.000.000 gene.[105] Trong khi các kết quả đo thực nghiệm sơ bộ ban đầu cho thấy số lượng này trong khoảng 50.000–100.000 gene được phiên mã (bằng phương pháp đánh dấu trình tự biểu hiện).[106] Sau đó, kết quả giải trình tự ở Dự án Bản đồ gene ở Người cho thấy nhiều trình tự được phiên mã là những biến thể khác của cùng một gen, và tổng số lượng gene mã hóa protein giảm xuống còn ~20.000[99] trong đó có 13 gene mã hóa nằm trong bộ gene ty thể.[97] Nghiên cứu sâu hơn từ dự án GENCODE, tiếp tục cho ước lượng số gene giảm xuống còn ~19.900.[107][108] Trong bộ gene ở người, chỉ 1–2% trong 3 tỷ cặp base DNA là đoạn mã hóa protein,[109][110] những đoạn còn lại là các DNA 'không mã hóa' bao gồm intron, retrotransposon, các trình tự điều hòa DNA và các đoạn DNA phiên mã thành RNA không mã hóa.[110][111] Trong mỗi tế bào ở sinh vật đa bào chứa toàn bộ gene nhưng không phải tất cả gene hoạt động trong từng tế bào.
Gene cơ bản
sửa
Các gene cơ bản là tập hợp những gene được cho là trọng yếu đối với sự sinh tồn của một sinh vật.[113] Định nghĩa này dựa trên giả sử sinh vật được cung cấp nguồn chất dinh dưỡng đầy đủ và không chịu các áp lực từ môi trường nó sống. Chỉ một phần nhỏ gene của một sinh vật là gene cơ bản. Ở vi khuẩn, ước tính có khoảng 250–400 gene cơ bản đối với Escherichia coli và Bacillus subtilis, mà số lượng này nhỏ hơn 10% tổng số gene của chúng.[114][115][116] Một nửa các gen này là ortholog trong cả hai vi khuẩn và phần lớn tham gia vào sinh tổng hợp protein.[116] Ở nấm men Saccharomyces cerevisiae số lượng gene cơ bản cao hơn một chút, ở mức 1000 gene (~20% bộ gene của nó).[117] Mặc dù số lượng này càng khó xác định hơn ở sinh vật nhân thực bậc cao, ước tính ở chuột và người có khoảng 2000 gene cơ bản (~10% bộ gene).[118] Sinh vật tổng hợp, Syn 3, chứa 473 gene cơ bản và một số gene gần cơ bản (cần thiết cho sự sinh trưởng nhanh), mặc dù có 149 gene là chưa rõ chức năng.[112]
Các gene cơ bản bao gồm gene giữ nhà (housekeeping gene, chúng đặc biệt quan trọng cho các chức năng cơ bản của tế bào)[119] cũng như các gen được biểu hiện ở những thời điểm khác nhau trong các giai đoạn phát triển hoặc vòng đời sinh học.[120] Các gene giữ nhà được sử dụng trong kiểm soát khoa học khi thực hiện phân tích biểu hiện gen, vì chúng được biểu hiện cấu thành ở mức độ tương đối không đổi.
Định danh gene và bộ gene
sửaĐịnh danh gene được quản lý bởi Ủy ban định danh gene (HUGO) cho mỗi gene đã biết ở người tuân theo dạng thức đã được phê chuẩn về tên của một gen và ký hiệu tương ứng của nó, cho phép dữ liệu về nó có thể truy cập được thông qua cơ sở dữ liệu quản lý bởi Ủy ban này. Các ký hiệu được chọn duy nhất cho từng gene (mặc dù đôi lúc phê duyệt lại ký hiệu thay đổi). Các ký hiệu được ưu tiên đặt sao cho giữ sự nhất quán với các thành viên khác trong một gia đình gene và với các gen tương đồng ở những loài khác, đặc biệt là ở chuột do nó được sử dụng là một trong những sinh vật mô hình.[121]
Kỹ thuật di truyền
sửaKỹ thuật di truyền là các phương pháp chỉnh sửa bộ gene của một sinh vật nhờ các công nghệ sinh học. Từ thập niên 1970, nhiều kỹ thuật đã được phát triển để thực hiện thêm, loại bỏ hoặc sửa đổi các gen trong sinh vật.[122] Các kỹ thuật chỉnh sửa bộ gene được phát triển gần đây sử dụng các enzyme nuclease để tạo ra các đích sửa chữa DNA trong nhiễm sắc thể hoặc là phá vỡ hay chỉnh sửa một gen khi vị trí đứt gãy được sửa đổi.[123][124][125][126] Ngành sinh học tổng hợp (synthetic biology) đôi khi sử dụng các kỹ thuật liên quan để mở rộng nghiên cứu di truyền trên một sinh vật.[127]
Kỹ thuật di truyền hiện nay là công cụ nghiên cứu thường xuyên áp dụng cho các sinh vật mô hình. Ví dụ, có thể dễ dàng thêm vào các gen ở vi khuẩn[128] và nòi giống ở chuột knockout với một chức năng gene đặc biệt bị bất hoạt nhằm nghiên cứu chức năng của các gen.[129][130] Nhiều sinh vật đã được sửa đổi về mặt di truyền để ứng dụng trong nông nghiệp (thực phẩm biến đổi gene), công nghiệp công nghệ sinh học, và y học.
Đối với sinh vật đa bào, đặc biệt là các phôi được tác động theo ý muốn trước khi trưởng thành hay các sinh vật chỉnh sửa gen (GMO).[131] Tuy nhiên, bộ gene của các tế bào trong sinh vật trưởng thành có thể chỉnh sửa bằng cách sử dụng các kỹ thuật liệu pháp gen để điều trị các bệnh liên quan tới di truyền.
Xem thêm
sửaTham khảo
sửaSách tham khảo chính
sửaAlberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molecular Biology of the Cell . New York: Garland Science. ISBN 978-0-8153-3218-3. – Có thể truy cập miễn phí ấn bản lần 4 của cuốn sách tại trang của NCBI.![]()
Chú thích
sửa- ^ Karen Hopkin. “The Evolving Definition of a Gene: With the discovery that nearly all of the genome is transcribed, the definition of a "gene" needs another revision”.
- ^ “Gene - Biology Dictionary”.
- ^ “What is a gene?”.
- ^ a b Campbell và cộng sự: "Sinh học" - Nhà xuất bản Giáo dục, 2010.
- ^ SGK "Sinh học 9" và "Sinh học 12" - Nhà xuất bản Giáo dục, 2017.
- ^ Petter Portin & Adam Wilkins. “The Evolving Definition of the Term "Gene"”.
- ^ a b Gericke, Niklas Markus; Hagberg, Mariana (ngày 5 tháng 12 năm 2006). “Definition of historical models of gene function and their relation to students' understanding of genetics”. Science & Education. 16 (7–8): 849–881. Bibcode:2007Sc&Ed..16..849G. doi:10.1007/s11191-006-9064-4.
- ^ Pearson H (tháng 5 năm 2006). “Genetics: what is a gene?”. Nature. 441 (7092): 398–401. Bibcode:2006Natur.441..398P. doi:10.1038/441398a. PMID 16724031.
- ^ a b c Pennisi E (tháng 6 năm 2007). “Genomics. DNA study forces rethink of what it means to be a gene”. Science. 316 (5831): 1556–1557. doi:10.1126/science.316.5831.1556. PMID 17569836.
- ^ a b Johannsen, W. (1905). Arvelighedslærens elementer ("The Elements of Heredity". Copenhagen). Rewritten, enlarged and translated into German as Elemente der exakten Erblichkeitslehre (Jena: Gustav Fischer, 1905; Scanned full text. Lưu trữ 2009-05-30 tại Wayback Machine
- ^ Noble D (tháng 9 năm 2008). “Genes and causation”. Philosophical Transactions of the Royal Society of London. Series A, Mathematical and Physical Sciences. 366 (1878): 3001–3015. Bibcode:2008RSPTA.366.3001N. doi:10.1098/rsta.2008.0086. PMID 18559318. Bản gốc (Free full text) lưu trữ ngày 27 tháng 3 năm 2020. Truy cập ngày 3 tháng 6 năm 2018.
- ^ Magner, Lois N. (2002). History of the Life Sciences . New York: Marcel Dekker, Inc. tr. 380. ISBN 978-0-2039-1100-6.
- ^ Gros, Franc̜ois (1992). The Gene Civilization . New York: McGraw Hill. tr. 28. ISBN 978-0-07-024963-9.
- ^ Moore, Randy (2001). “The "Rediscovery" of Mendel's Work” (PDF). Bioscene. 27 (2): 13–24. Bản gốc (PDF) lưu trữ ngày 11 tháng 2 năm 2016.
- ^ “genesis”. Từ điển tiếng Anh Oxford . Nhà xuất bản Đại học Oxford. (Subscription or participating institution membership required.)
- ^ Magner, Lois N. (2002). A History of the Life Sciences . Marcel Dekker, CRC Press. tr. 371. ISBN 978-0-203-91100-6.
- ^ Henig, Robin Marantz (2000). The Monk in the Garden: The Lost and Found Genius of Gregor Mendel, the Father of Genetics. Boston: Houghton Mifflin. tr. 1–9. ISBN 978-0395-97765-1.
- ^ Vries, H. de, Intracellulare Pangenese, Verlag von Gustav Fischer, Jena, 1889. Translated in 1908 from German to English by C. Stuart Gager as Intracellular Pangenesis, Open Court Publishing Co., Chicago, 1910
- ^ “The Chromosomes in Heredity” (PDF). Biological Bulletin. 4: 231-251. 1903.
- ^ a b c Gerstein MB (tháng 6 năm 2007). “What is a gene, post-ENCODE? History and updated definition”. Genome Research. 17 (6): 669–681. doi:10.1101/gr.6339607. PMID 17567988.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Fisher, R. A.; De Beer, G. R. (1947). “Thomas Hunt Morgan. 1866-1945”. Obituary Notices of Fellows of the Royal Society. 5 (15): 451–466. doi:10.1098/rsbm.1947.0011. JSTOR 769094.
- ^ Avery, OT; MacLeod, CM; McCarty, M (1944). “Studies on the Chemical Nature of the Substance Inducing Transformation of Pneumococcal Types: Induction of Transformation by a Desoxyribonucleic Acid Fraction Isolated from Pneumococcus Type III”. The Journal of Experimental Medicine. 79 (2): 137–58. doi:10.1084/jem.79.2.137. PMC 2135445. PMID 19871359. Reprint: Avery, OT; MacLeod, CM; McCarty, M (1979). “Studies on the chemical nature of the substance inducing transformation of pneumococcal types. Inductions of transformation by a desoxyribonucleic acid fraction isolated from pneumococcus type III”. The Journal of Experimental Medicine. 149 (2): 297–326. doi:10.1084/jem.149.2.297. PMC 2184805. PMID 33226.
- ^ Hershey, AD; Chase, M (1952). “Independent functions of viral protein and nucleic acid in growth of bacteriophage”. The Journal of General Physiology. 36 (1): 39–56. doi:10.1085/jgp.36.1.39. PMC 2147348. PMID 12981234.
- ^ Judson, Horace (1979). The Eighth Day of Creation: Makers of the Revolution in Biology. Cold Spring Harbor Laboratory Press. tr. 51–169. ISBN 0-87969-477-7.
- ^ Watson, J. D.; Crick, FH (1953). “Molecular Structure of Nucleic Acids: A Structure for Deoxyribose Nucleic Acid” (PDF). Nature. 171 (4356): 737–8. Bibcode:1953Natur.171..737W. doi:10.1038/171737a0. PMID 13054692.
- ^ Benzer S (1955). “Fine Structure of A Genetic Region in Bacteriophage”. Proc. Natl. Acad. Sci. U.S.A. 41 (6): 344–54. doi:10.1073/pnas.41.6.344. PMC 528093. PMID 16589677.
- ^ Benzer S (1959). “On the Topology of the Genetic Fine Structure”. Proc. Natl. Acad. Sci. U.S.A. 45 (11): 1607–20. doi:10.1073/pnas.45.11.1607. PMC 222769. PMID 16590553.
- ^ a b Beadle G.W, Tatum E.L (ngày 15 tháng 11 năm 1941). “Genetic Control of Biochemical Reactions in Neurospora”. PNAS. 27 (11): 499–506. Bibcode:1941PNAS...27..499B. doi:10.1073/pnas.27.11.499. PMC 1078370. PMID 16588492.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Berg P, Singer M. George Beadle, an uncommon farmer: the emergence of genetics in the 20th century, CSHL Press, 2003. ISBN 0-87969-688-5, ISBN 978-0-87969-688-7
- ^ M, Fiers W (tháng 5 năm 1972). “Nucleotide sequence of the gene coding for the bacteriophage MS2 coat protein”. Nature. 237 (5350): 82–8. Bibcode:1972Natur.237...82J. doi:10.1038/237082a0. PMID 4555447.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Sanger, F (1977). “DNA sequencing with chain-terminating inhibitors”. Proceedings of the National Academy of Sciences of the United States of America. 74 (12): 5463–7. Bibcode:1977PNAS...74.5463S. doi:10.1073/pnas.74.12.5463. PMC 431765. PMID 271968.
- ^ Adams, Jill U. (2008). “DNA Sequencing Technologies”. Nature Education Knowledge. SciTable. Nature Publishing Group. 1 (1): 193.
- ^ Huxley, Julian (1942). Evolution: the Modern Synthesis. Cambridge, Mass.: MIT Press. ISBN 978-0262513661.
- ^ Williams, George C. (2001). Adaptation and Natural Selection a Critique of Some Current Evolutionary Thought . Princeton: Princeton University Press. ISBN 9781400820108.
- ^ Dawkins, Richard (1977). The selfish gene . London: Oxford University Press. ISBN 0-19-857519-X.
- ^ Dawkins, Richard (1989). The extended phenotype . Oxford: Oxford University Press. ISBN 0-19-286088-7.
- ^ a b c d e f g h i j k l m n o p q r s t u v w x y z aa ab ac ad ae af ag ah ai aj ak Alberts B, Johnson A, Lewis J, Raff M, Roberts K, Walter P (2002). Molecular Biology of the Cell . New York: Garland Science. ISBN 978-0-8153-3218-3.
- ^ Stryer L, Berg JM, Tymoczko JL (2002). Biochemistry (ấn bản 5). San Francisco: W.H. Freeman. ISBN 0-7167-4955-6.
- ^ Bolzer, Andreastitle=Three-Dimensional Maps of All Chromosomes in Human Male Fibroblast Nuclei and Prometaphase Rosettes (2005). PLoS Biology. 3 (5): e157. doi:10.1371/journal.pbio.0030157. PMC 1084335. PMID 15839726 //www.ncbi.nlm.nih.gov/pmc/articles/PMC1084335.
|title=trống hay bị thiếu (trợ giúp)
- ^ Braig M, Schmitt CA (tháng 3 năm 2006). “Oncogene-induced senescence: putting the brakes on tumor development”. Cancer Research. 66 (6): 2881–4. doi:10.1158/0008-5472.CAN-05-4006. PMID 16540631.
- ^ a b Bennett, PM (tháng 3 năm 2008). “Plasmid encoded antibiotic resistance: acquisition and transfer of antibiotic resistance genes in bacteria”. British Journal of Pharmacology. 153 Suppl 1: S347–57. doi:10.1038/sj.bjp.0707607. PMC 2268074. PMID 18193080.
- ^ International Human Genome Sequencing Consortium (tháng 10 năm 2004). “Finishing the euchromatic sequence of the human genome”. Nature. 431 (7011): 931–45. Bibcode:2004Natur.431..931H. doi:10.1038/nature03001. PMID 15496913.
- ^ a b Shafee, Thomas; Lowe, Rohan (2017). “Eukaryotic and prokaryotic gene structure”. WikiJournal of Medicine. 4 (1). doi:10.15347/wjm/2017.002. ISSN 2002-4436.
- ^ Mortazavi A (tháng 7 năm 2008). “Mapping and quantifying mammalian transcriptomes by RNA-Seq”. Nature Methods. 5 (7): 621–8. doi:10.1038/nmeth.1226. PMID 18516045.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Pennacchio, L. A. (2013). “Enhancers: Five essential questions”. Nature Reviews Genetics. 14 (4): 288–95. doi:10.1038/nrg3458. PMC 4445073. PMID 23503198.
- ^ Maston, G. A. (2006). “Transcriptional Regulatory Elements in the Human Genome”. Annual Review of Genomics and Human Genetics. 7: 29–59. doi:10.1146/annurev.genom.7.080505.115623. PMID 16719718.
- ^ Mignonepmc = 139023, Flavio (ngày 28 tháng 2 năm 2002). “Untranslated regions of mRNAs”. Genome Biology. 3 (3): reviews0004. doi:10.1186/gb-2002-3-3-reviews0004. ISSN 1465-6906. PMID 11897027. Bản gốc lưu trữ ngày 29 tháng 9 năm 2015. Truy cập ngày 3 tháng 6 năm 2018.
- ^ Bicknell AA (tháng 12 năm 2012). “Introns in UTRs: why we should stop ignoring them”. BioEssays. 34 (12): 1025–34. doi:10.1002/bies.201200073. PMID 23108796.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Salgado, H. (2000). “Operons in Escherichia coli: Genomic analyses and predictions”. Proceedings of the National Academy of Sciences. 97 (12): 6652–6657. Bibcode:2000PNAS...97.6652S. doi:10.1073/pnas.110147297. PMC 18690. PMID 10823905.
- ^ Blumenthal, Thomas (tháng 11 năm 2004). “Operons in eukaryotes”. Briefings in Functional Genomics & Proteomics. 3 (3): 199–211. doi:10.1093/bfgp/3.3.199. ISSN 2041-2649. PMID 15642184.
- ^ a b Jacob F; Monod J (tháng 6 năm 1961). “Genetic regulatory mechanisms in the synthesis of proteins”. Journal of Molecular Biology. 3 (3): 318–56. doi:10.1016/S0022-2836(61)80072-7. PMID 13718526.
- ^ Spilianakis CG (tháng 6 năm 2005). “Interchromosomal associations between alternatively expressed loci”. Nature. 435 (7042): 637–45. Bibcode:2005Natur.435..637S. doi:10.1038/nature03574. PMID 15880101.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Williams, Atitle=Interchromosomal association and gene regulation in trans. (tháng 4 năm 2010). Trends in Genetics. 26 (4): 188–97. doi:10.1016/j.tig.2010.01.007. PMC 2865229. PMID 20236724 //www.ncbi.nlm.nih.gov/pmc/articles/PMC2865229.
|title=trống hay bị thiếu (trợ giúp) - ^ Horowitz NH (2004). “A centennial: George W. Beadle, 1903-1989”. Genetics. 166 (1): 1–10. doi:10.1534/genetics.166.1.1. PMC 1470705. PMID 15020400.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Marande W, Burger G (tháng 10 năm 2007). “Mitochondrial DNA as a genomic jigsaw puzzle”. Science. AAAS. 318 (5849): 415. Bibcode:2007Sci...318..415M. doi:10.1126/science.1148033. PMID 17947575.
- ^ Parra G (tháng 1 năm 2006). “Tandem chimerism as a means to increase protein complexity in the human genome”. Genome Research. 16 (1): 37–44. doi:10.1101/gr.4145906. PMC 1356127. PMID 16344564.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ a b Eddy SR (tháng 12 năm 2001). “Non-coding RNA genes and the modern RNA world”. Nat. Rev. Genet. 2 (12): 919–29. doi:10.1038/35103511. PMID 11733745.
- ^ Crick F (1961). “General nature of the genetic code for proteins”. Nature. 192: 1227–32. doi:10.1038/1921227a0. PMID 13882203.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Crick, Francis (1962). The genetic code. WH Freeman and Company. PMID 13882204.
- ^ Woodson SA (tháng 5 năm 1998). “Ironing out the kinks: splicing and translation in bacteria”. Genes & Development. 12 (9): 1243–7. doi:10.1101/gad.12.9.1243. PMID 9573040.
- ^ Koonin, Eugene V.title=Evolution and Taxonomy of Positive-Strand RNA Viruses: Implications of Comparative Analysis of Amino Acid Sequences (tháng 1 năm 1993). Critical Reviews in Biochemistry and Molecular Biology. 28 (5): 375–430. doi:10.3109/10409239309078440. PMID 8269709.
|title=trống hay bị thiếu (trợ giúp) - ^ Domingo, Esteban (2001). “RNA Virus Genomes”. ELS. doi:10.1002/9780470015902.a0001488.pub2. ISBN 0470016175.
- ^ Domingo, Etitle=Basic concepts in RNA virus evolution. (tháng 6 năm 1996). FASEB Journal. 10 (8): 859–64. PMID 8666162.
|title=trống hay bị thiếu (trợ giúp) - ^ Morris, KV; Mattick, JS (tháng 6 năm 2014). “The rise of regulatory RNA”. Nature Reviews Genetics. 15 (6): 423–37. doi:10.1038/nrg3722. PMC 4314111. PMID 24776770.
- ^ Miko, Ilona (2008). “Gregor Mendel and the Principles of Inheritance”. Nature Education Knowledge. SciTable. Nature Publishing Group. 1 (1): 134.
- ^ Chial, Heidi (2008). “Mendelian Genetics: Patterns of Inheritance and Single-Gene Disorders”. Nature Education Knowledge. SciTable. Nature Publishing Group. 1 (1): 63.
- ^ McCarthy D (1976). “DNA elongation rates and growing point distributions of wild-type phage T4 and a DNA-delay amber mutant”. J. Mol. Biol. 106 (4): 963–81. doi:10.1016/0022-2836(76)90346-6. PMID 789903.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ a b Mader, Sylvia (2007). Biology Ninth Edition. New York: McGraw-Hill. tr. 209. ISBN 978-0-07-325839-3.
- ^ Lobo, Ingrid; Shaw, Kelly (2008). “Discovery and Types of Genetic Linkage”. Nature Education Knowledge. SciTable. Nature Publishing Group. 1 (1): 139.
- ^ Nachman MW, Crowell SL (tháng 9 năm 2000). “Estimate of the mutation rate per nucleotide in humans”. Genetics. 156 (1): 297–304. PMC 1461236. PMID 10978293.
- ^ Roach JC (tháng 4 năm 2010). “Analysis of genetic inheritance in a family quartet by whole-genome sequencing”. Science. 328 (5978): 636–9. Bibcode:2010Sci...328..636R. doi:10.1126/science.1186802. PMC 3037280. PMID 20220176.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ a b Drake JW (tháng 4 năm 1998). “Rates of spontaneous mutation”. Genetics. 148 (4): 1667–86. PMC 1460098. PMID 9560386.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ “What kinds of gene mutations are possible?”. Genetics Home Reference. United States National Library of Medicine. ngày 11 tháng 5 năm 2015. Truy cập ngày 19 tháng 5 năm 2015.
- ^ Andrews, Christine A. (2010). “Natural Selection, Genetic Drift, and Gene Flow Do Not Act in Isolation in Natural Populations”. Nature Education Knowledge. SciTable. Nature Publishing Group. 3 (10): 5.
- ^ Patterson, C (tháng 11 năm 1988). “Homology in classical and molecular biology”. Molecular Biology and Evolution. 5 (6): 603–25. PMID 3065587.
- ^ Studer, RA; Robinson-Rechavi, M (tháng 5 năm 2009). “How confident can we be that orthologs are similar, but paralogs differ?”. Trends in Genetics. 25 (5): 210–6. doi:10.1016/j.tig.2009.03.004. PMID 19368988.
- ^ Altenhoff, AMtitle=Resolving the ortholog conjecture: orthologs tend to be weakly, but significantly, more similar in function than paralogs. (2012). PLOS Computational Biology. 8 (5): e1002514. doi:10.1371/journal.pcbi.1002514. PMC 3355068. PMID 22615551 //www.ncbi.nlm.nih.gov/pmc/articles/PMC3355068.
|title=trống hay bị thiếu (trợ giúp)
- ^ Nosil, Patriktitle=Divergent selection and heterogeneous genomic divergence (tháng 2 năm 2009). Molecular Ecology. 18 (3): 375–402. doi:10.1111/j.1365-294X.2008.03946.x. PMID 19143936.
|title=trống hay bị thiếu (trợ giúp) - ^ Emery, Laura. “Introduction to Phylogenetics”. EMBL-EBI. Truy cập ngày 19 tháng 5 năm 2015.
- ^ Mitchell, Matthew W.; Gonder, Mary Katherine (2013). “Primate Speciation: A Case Study of African Apes”. Nature Education Knowledge. SciTable. Nature Publishing Group. 4 (2): 1.
- ^ a b Guerzoni, D; McLysaght, A (tháng 11 năm 2011). “De novo origins of human genes”. PLOS Genetics. 7 (11): e1002381. doi:10.1371/journal.pgen.1002381. PMC 3213182. PMID 22102832.
- ^ Reams, AB; Roth, JR (ngày 2 tháng 2 năm 2015). “Mechanisms of gene duplication and amplification”. Cold Spring Harbor perspectives in biology. 7 (2): a016592. doi:10.1101/cshperspect.a016592. PMC 4315931. PMID 25646380.
- ^ Demuth, JPtitle=The evolution of mammalian gene families (ngày 20 tháng 12 năm 2006). PLoS ONE. 1: e85. Bibcode:2006PLoSO...1...85D. doi:10.1371/journal.pone.0000085. PMC 1762380. PMID 17183716 //www.ncbi.nlm.nih.gov/pmc/articles/PMC1762380.
|title=trống hay bị thiếu (trợ giúp)
- ^ Knowles, DG; McLysaght, A (tháng 10 năm 2009). “Recent de novo origin of human protein-coding genes”. Genome Research. 19 (10): 1752–9. doi:10.1101/gr.095026.109. PMC 2765279. PMID 19726446.
- ^ Wu, DDtitle=De novo origin of human protein-coding genes. (tháng 11 năm 2011). PLOS Genetics. 7 (11): e1002379. doi:10.1371/journal.pgen.1002379. PMC 3213175. PMID 22102831 //www.ncbi.nlm.nih.gov/pmc/articles/PMC3213175.
|title=trống hay bị thiếu (trợ giúp)
- ^ McLysaght, Aoife; Guerzoni, Daniele (ngày 31 tháng 8 năm 2015). “New genes from non-coding sequence: the role of de novo protein-coding genes in eukaryotic evolutionary innovation”. Philosophical Transactions of the Royal Society B: Biological Sciences. 370 (1678): 20140332. doi:10.1098/rstb.2014.0332. PMC 4571571. PMID 26323763.
- ^ Neme, Rafik; Tautz, Diethard (2013). “Phylogenetic patterns of emergence of new genes support a model of frequent de novo evolution”. BMC Genomics. 14 (1): 117. doi:10.1186/1471-2164-14-117. PMC 3616865. PMID 23433480.
- ^ Treangen, TJ; Rocha, EP (ngày 27 tháng 1 năm 2011). “Horizontal transfer, not duplication, drives the expansion of protein families in prokaryotes”. PLOS Genetics. 7 (1): e1001284. doi:10.1371/journal.pgen.1001284. PMC 3029252. PMID 21298028.
- ^ Ochman, Htitle=Lateral gene transfer and the nature of bacterial innovation. (ngày 18 tháng 5 năm 2000). Nature. 405 (6784): 299–304. Bibcode:2000Natur.405..299O. doi:10.1038/35012500. PMID 10830951.
|title=trống hay bị thiếu (trợ giúp) - ^ Keeling, PJ; Palmer, JD (tháng 8 năm 2008). “Horizontal gene transfer in eukaryotic evolution”. Nature Reviews Genetics. 9 (8): 605–18. doi:10.1038/nrg2386. PMID 18591983.
- ^ Schönknecht, Gtitle=Gene transfer from bacteria and archaea facilitated evolution of an extremophilic eukaryote. (ngày 8 tháng 3 năm 2013). Science. 339 (6124): 1207–10. Bibcode:2013Sci...339.1207S. doi:10.1126/science.1231707. PMID 23471408.
|title=trống hay bị thiếu (trợ giúp) - ^ Ridley, M. (2006). Genome. New York, NY: Harper Perennial. ISBN 0-06-019497-9
- ^ Watson, JD(2004). "Ch9-10", Molecular Biology of the Gene, 5th ed., Peason Benjamin Cummings; CSHL Press.
- ^ “Understanding the Basics”. The Human Genome Project. Truy cập ngày 26 tháng 4 năm 2015.
- ^ “WS227 Release Letter”. WormBase. ngày 10 tháng 8 năm 2011. Bản gốc lưu trữ ngày 28 tháng 11 năm 2013. Truy cập ngày 19 tháng 11 năm 2013.
- ^ Yu, J. (ngày 5 tháng 4 năm 2002). “A Draft Sequence of the Rice Genome (Oryza sativa L. ssp. indica)”. Science. 296 (5565): 79–92. Bibcode:2002Sci...296...79Y. doi:10.1126/science.1068037. PMID 11935017.
- ^ a b Anderson, S.title=Sequence and organization of the human mitochondrial genome (ngày 9 tháng 4 năm 1981). Nature. 290 (5806): 457–465. Bibcode:1981Natur.290..457A. doi:10.1038/290457a0. PMID 7219534.
|title=trống hay bị thiếu (trợ giúp) - ^ Adams, M. D. (ngày 24 tháng 3 năm 2000). “The Genome Sequence of Drosophila melanogaster”. Science. 287 (5461): 2185–2195. Bibcode:2000Sci...287.2185.. doi:10.1126/science.287.5461.2185. PMID 10731132.
- ^ a b Pertea, Mihaela; Salzberg, Steven L (2010). “Between a chicken and a grape: estimating the number of human genes”. Genome Biology. 11 (5): 206. doi:10.1186/gb-2010-11-5-206. PMC 2898077. PMID 20441615.
- ^ Belyi, V. A.title=Sequences from Ancestral Single-Stranded DNA Viruses in Vertebrate Genomes: the Parvoviridae and Circoviridae Are More than 40 to 50 Million Years Old (ngày 22 tháng 9 năm 2010). Journal of Virology. 84 (23): 12458–12462. doi:10.1128/JVI.01789-10. PMC 2976387. PMID 20861255 //www.ncbi.nlm.nih.gov/pmc/articles/PMC2976387.
|title=trống hay bị thiếu (trợ giúp) - ^ Flores, Ricardotitle=Viroids: The Noncoding Genomes (tháng 2 năm 1997). Seminars in Virology. 8 (1): 65–73. doi:10.1006/smvy.1997.0107.
|title=trống hay bị thiếu (trợ giúp) - ^ Zonneveld, B. J. M. (2010). “New Record Holders for Maximum Genome Size in Eudicots and Monocots”. Journal of Botany. 2010: 1–4. doi:10.1155/2010/527357.
- ^ Yu J (tháng 4 năm 2002). “A draft sequence of the rice genome (Oryza sativa L. ssp. indica)”. Science. 296 (5565): 79–92. Bibcode:2002Sci...296...79Y. doi:10.1126/science.1068037. PMID 11935017.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Perez-Iratxeta C (tháng 12 năm 2007). “Towards completion of the Earth's proteome”. EMBO Reports. 8 (12): 1135–1141. doi:10.1038/sj.embor.7401117. PMC 2267224. PMID 18059312.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Kauffman SA (1969). “Metabolic stability and epigenesis in randomly constructed genetic nets”. Journal of Theoretical Biology. Elsevier. 22 (3): 437–467. doi:10.1016/0022-5193(69)90015-0. PMID 5803332.
- ^ Schuler GD (tháng 10 năm 1996). “A gene map of the human genome”. Science. 274 (5287): 540–6. Bibcode:1996Sci...274..540S. doi:10.1126/science.274.5287.540. PMID 8849440.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ “Statistics about all Human GENCODE releases (Version 28 - November 2017)”. ENCODE. Bản gốc lưu trữ ngày 14 tháng 4 năm 2018. Truy cập 18 tháng 4 năm 2018.
- ^ Chi, Kelly Rae (ngày 17 tháng 8 năm 2016). “The dark side of the human genome”. Nature (bằng tiếng Anh). 538 (7624): 275–277. doi:10.1038/538275a.
- ^ “The 99 percent... of the Human Genome”. Jonathan Henninger. Harvard University. ngày 1 tháng 10 năm 2012. Truy cập ngày 12 tháng 10 năm 2015.
- ^ a b Claverie JM (tháng 9 năm 2005). “Fewer genes, more noncoding RNA”. Science. 309 (5740): 1529–30. Bibcode:2005Sci...309.1529C. doi:10.1126/science.1116800. PMID 16141064.
- ^ Carninci P, Hayashizaki Y (tháng 4 năm 2007). “Noncoding RNA transcription beyond annotated genes”. Current Opinion in Genetics & Development. 17 (2): 139–44. doi:10.1016/j.gde.2007.02.008. PMID 17317145.
- ^ a b Hutchison, Clyde A. (ngày 25 tháng 3 năm 2016). “Design and synthesis of a minimal bacterial genome”. Science (bằng tiếng Anh). 351 (6280): aad6253. Bibcode:2016Sci...351.....H. doi:10.1126/science.aad6253. ISSN 0036-8075. PMID 27013737.
- ^ Glass, J. I.title=Essential genes of a minimal bacterium (ngày 3 tháng 1 năm 2006). Proceedings of the National Academy of Sciences. 103 (2): 425–430. Bibcode:2006PNAS..103..425G. doi:10.1073/pnas.0510013103. PMC 1324956. PMID 16407165 //www.ncbi.nlm.nih.gov/pmc/articles/PMC1324956.
|title=trống hay bị thiếu (trợ giúp) - ^ Gerdes, SYtitle=Experimental determination and system level analysis of essential genes in Escherichia coli MG1655. (tháng 10 năm 2003). Journal of Bacteriology. 185 (19): 5673–84. doi:10.1128/jb.185.19.5673-5684.2003. PMC 193955. PMID 13129938 https://archive.org/details/sim_journal-of-bacteriology_2003-10_185_19/page/5673.
|title=trống hay bị thiếu (trợ giúp) - ^ Baba, Ttitle=Construction of Escherichia coli K-12 in-frame, single-gene knockout mutants: the Keio collection. (2006). Molecular Systems Biology. 2: 2006.0008. doi:10.1038/msb4100050. PMC 1681482. PMID 16738554 //www.ncbi.nlm.nih.gov/pmc/articles/PMC1681482.
|title=trống hay bị thiếu (trợ giúp) - ^ a b Juhas, Mtitle=Bacillus subtilis and Escherichia coli essential genes and minimal cell factories after one decade of genome engineering. (tháng 11 năm 2014). Microbiology. 160 (Pt 11): 2341–51. doi:10.1099/mic.0.079376-0. PMID 25092907.
|title=trống hay bị thiếu (trợ giúp) - ^ Tu, Ztitle=Further understanding human disease genes by comparing with housekeeping genes and other genes (ngày 21 tháng 2 năm 2006). BMC Genomics. 7: 31. doi:10.1186/1471-2164-7-31. PMC 1397819. PMID 16504025 //www.ncbi.nlm.nih.gov/pmc/articles/PMC1397819.
|title=trống hay bị thiếu (trợ giúp)
- ^ Georgi, Btitle=From mouse to human: evolutionary genomics analysis of human orthologs of essential genes. (tháng 5 năm 2013). PLOS Genetics. 9 (5): e1003484. doi:10.1371/journal.pgen.1003484. PMC 3649967. PMID 23675308 //www.ncbi.nlm.nih.gov/pmc/articles/PMC3649967.
|title=trống hay bị thiếu (trợ giúp)
- ^ Eisenberg, E; Levanon, EY (tháng 10 năm 2013). “Human housekeeping genes, revisited”. Trends in Genetics. 29 (10): 569–74. doi:10.1016/j.tig.2013.05.010. PMID 23810203.
- ^ Amsterdam, A; Hopkins, N (tháng 9 năm 2006). “Mutagenesis strategies in zebrafish for identifying genes involved in development and disease”. Trends in Genetics. 22 (9): 473–8. doi:10.1016/j.tig.2006.06.011. PMID 16844256.
- ^ “About the HGNC”. HGNC Database of Human Gene Names. HUGO Gene Nomenclature Committee. Bản gốc lưu trữ ngày 26 tháng 3 năm 2023. Truy cập ngày 14 tháng 5 năm 2015.
- ^ Stanley N. Cohen; Annie C. Y. Chang (ngày 1 tháng 5 năm 1973). “Recircularization and Autonomous Replication of a Sheared R-Factor DNA Segment in Escherichia coli Transformants”. PNAS. 70: 1293–1297. doi:10.1073/pnas.70.5.1293. PMC 433482. Bản gốc lưu trữ ngày 21 tháng 5 năm 2019. Truy cập ngày 17 tháng 7 năm 2010.
- ^ Esvelt, KM.; Wang, HH. (2013). “Genome-scale engineering for systems and synthetic biology”. Mol Syst Biol. 9 (1): 641. doi:10.1038/msb.2012.66. PMC 3564264. PMID 23340847.
- ^ Tan, WS. (2012). “Precision editing of large animal genomes”. Adv Genet. Advances in Genetics. 80: 37–97. doi:10.1016/B978-0-12-404742-6.00002-8. ISBN 9780124047426. PMC 3683964. PMID 23084873.
- ^ Puchta, H.; Fauser, F. (2013). “Gene targeting in plants: 25 years later”. Int. J. Dev. Biol. 57 (6–7–8): 629–637. doi:10.1387/ijdb.130194hp.
- ^ Ran FA (2013). “Genome engineering using the CRISPR-Cas9 system”. Nat Protoc. 8 (11): 2281–308. doi:10.1038/nprot.2013.143. PMC 3969860. PMID 24157548.Quản lý CS1: sử dụng tham số tác giả (liên kết)
- ^ Kittleson, Joshua (2012). “Successes and failures in modular genetic engineering”. Current Opinion in Chemical Biology. 16 (3–4): 329–336. doi:10.1016/j.cbpa.2012.06.009. PMID 22818777.
- ^ Berg, P.; Mertz, J. E. (2010). “Personal Reflections on the Origins and Emergence of Recombinant DNA Technology”. Genetics. 184 (1): 9–17. doi:10.1534/genetics.109.112144. PMC 2815933. PMID 20061565.
- ^ Austin, Christopher P. (tháng 9 năm 2004). “The Knockout Mouse Project”. Nature Genetics. 36 (9): 921–924. doi:10.1038/ng0904-921. ISSN 1061-4036. PMC 2716027. PMID 15340423.
- ^ Guan, Chunmei (2010). “A review of current large-scale mouse knockout efforts”. Genesis: NA. doi:10.1002/dvg.20594.
- ^ Deng C (2007). “In celebration of Dr. Mario R. Capecchi's Nobel Prize”. International Journal of Biological Sciences. 3 (7): 417–419. doi:10.7150/ijbs.3.417. PMC 2043165. PMID 17998949. Bản gốc lưu trữ ngày 20 tháng 5 năm 2012. Truy cập ngày 3 tháng 6 năm 2018.
Đọc thêm
sửa- Watson JD, Baker TA, Bell SP, Gann A, Levine M, Losick R (2013). Molecular Biology of the Gene (ấn bản 7). Benjamin Cummings. ISBN 978-0-321-90537-6.
- Ridley M (1999). Genome: The Autobiography of a Species in 23 Chapters. Fourth Estate. ISBN 0-00-763573-7.
- Brown, T (2002). Genomes (ấn bản 2). New York: Wiley-Liss. ISBN 0-471-25046-5.
Liên kết ngoài
sửa- Comparative Toxicogenomics Database
- DNA From The Beginning – a primer on genes and DNA
- Entrez Gene – a searchable database of genes
- IDconverter – converts gene IDs between public databases
- iHOP – Information Hyperlinked over Proteins Lưu trữ 2005-10-17 tại Wayback Machine
- TranscriptomeBrowser – Gene expression profile analysis Lưu trữ 2011-07-20 tại Wayback Machine
- The Protein Naming Utility, a database to identify and correct deficient gene names Lưu trữ 2012-12-21 tại Archive.today
- Genes – an Open Access journal
- IMPC (International Mouse Phenotyping Consortium) – Encyclopedia of mammalian gene function
- Global Genes Project – Leading non-profit organization supporting people living with genetic diseases
- ENCODE threads Explorer Characterization of intergenic regions and gene definition. Nature